硬件升级
首先,考虑对系统内存进行升级或者扩容,缓存越多则对磁盘的IO越少,那么性能就越好; 其次,如果应用系统于数据库在同一台主机中,可以考虑将两者分离,这个根据具体情况;
系统定向配置
配置方法
- 配置:
data/postgresql.conf - 也可以通过命令修改/查看参数:
ALTER SYSTEM SET、SHOW [name | ALL];-- 修改配置
ALTER SYSTEM SET
-- 查看当前配置
SHOW [name | ALL]
SELECT * FROM pg_settings WHERE pending_restart = true; - 另外还可以通过工具
pgtune进行参数调优
关键调优参数
max_connections最大连接数,这个参数设置大小和work_mem有一些关系。配置的越高,可能会占用系统更多的内存。通常可以设置数百个连接,如果要使用上千个连接,建议配置连接池来减少开销。
checkpoint_segments:检查点 segements,work_mem: 工作内存,random_page_cost: 随机页时间成本,shared_buffers
Effective_cache_size
分析查询性能
如果您的 SQL 语句执行得太慢,您想知道发生了什么以及如何修复它。在 SQL 中,很难看到引擎如何花费时间
EXPLAIN
查看语句的执行计划
EXPLAIN [ ( option [, ...] ) ] statement
EXPLAIN [ ANALYZE ] [ VERBOSE ] statement
where option can be one of:
ANALYZE [ boolean ]
VERBOSE [ boolean ]
BUFFERS [ boolean ]
SETTINGS [ boolean ]
其中:
- ANALYZE 选项为TRUE 会实际执行SQL,并获得相应的查询计划,默认为FALSE。如果优化一些修改数据的SQL 需要真实的执行但是不能影响现有的数据,可以放在一个事务中,分析完成后可以直接回滚。
- VERBOSE 选项为TRUE 会显示查询计划的附加信息,默认为FALSE。附加信息包括查询计划中每个节点(后面具体解释节点的含义)输出的列(Output),表的SCHEMA 信息,函数的SCHEMA 信息,表达式中列所属表的别名,被触发的触发器名称等。
- BUFFERS 选项为TRUE 会显示关于缓存的使用信息,默认为FALSE。该参数只能与ANALYZE 参数一起使用。缓冲区信息包括共享块(常规表或者索引块)、本地块(临时表或者索引块)和临时块(排序或者哈希等涉及到的短期存在的数据块)的命中块数,更新块数,挤出块数。
- SETTINGS:选项 v12+ ,并包括所有与输出中的默认值不同的性能相关参数。
EXPLAIN (ANALYZE,VERBOSE, BUFFERS)
SELECT "workflowProcessVersion".*, "workflowProcessHistories"."id" AS "workflowProcessHistories.id", "workflowProcessHistories"."procinst_id" AS "workflowProcessHistories.procinstId", "workflowProcessHistories"."form_data" AS "workflowProcessHistories.formData", "workflowProcessHistories"."create_at" AS "workflowProcessHistories.createAt", "workflowProcessHistories"."version_id" AS "workflowProcessHistories.versionId", "workflowProcessHistories"."apply_user" AS "workflowProcessHistories.applyUser" FROM (SELECT "workflowProcessVersion"."id", "workflowProcessVersion"."process_id" AS "processId", "workflowProcessVersion"."deployment_id" AS "deploymentId", "workflowProcessVersion"."procdef_id" AS "procdefId", "workflowProcessVersion"."proc_key" AS "procKey", "workflowProcessVersion"."current", "workflowProcessVersion"."create_at" AS "createAt", "workflowProcessVersion"."form_id" AS "formId", "workflowProcessVersion"."bpmn_json" AS "bpmnJson" FROM "workflow_process_version" AS "workflowProcessVersion" WHERE ( SELECT "version_id" FROM "workflow_process_history" AS "workflowProcessHistories" WHERE ("workflowProcessHistories"."procinst_id" = '2b38bb4a-db44-11ec-9537-82994f65ae9b' AND "workflowProcessHistories"."version_id" = "workflowProcessVersion"."id") LIMIT 10 ) IS NOT NULL LIMIT 10) AS "workflowProcessVersion" INNER JOIN "workflow_process_history" AS "workflowProcessHistories" ON "workflowProcessVersion"."id" = "workflowProcessHistories"."version_id" AND "workflowProcessHistories"."procinst_id" = '2b38bb4a-db44-11ec-9537-82994f65ae9b'
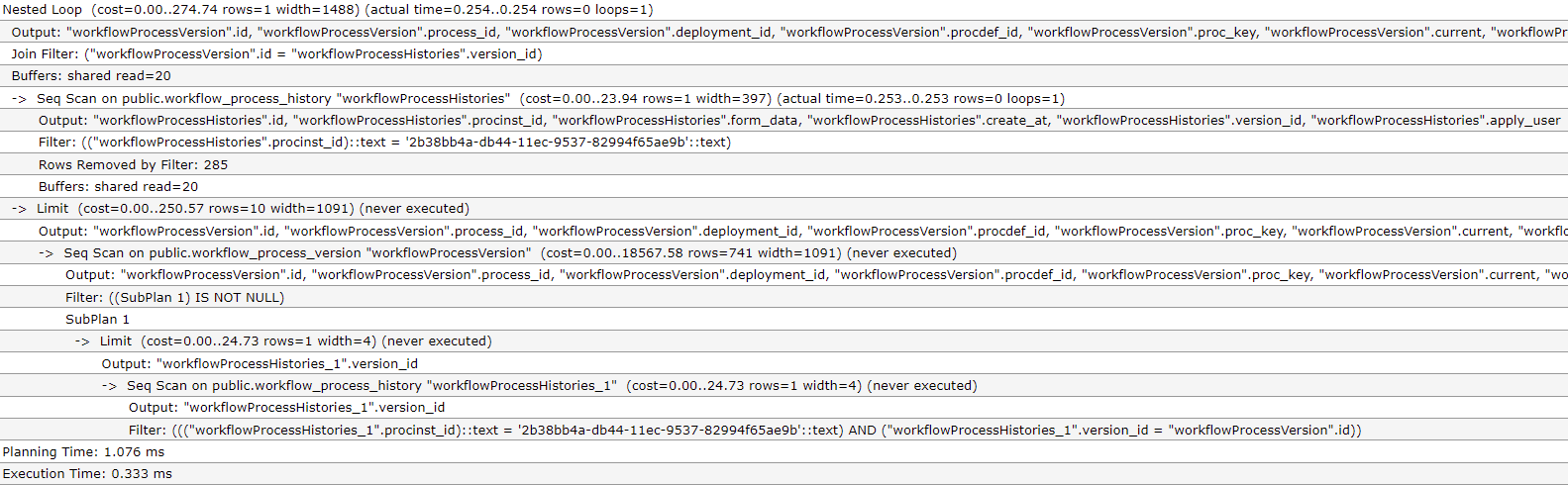
生成的查询计划:
QUERY PLAN
Nested Loop (cost=0.00..274.74 rows=1 width=1488) (actual time=0.254..0.254 rows=0 loops=1)
Output: "workflowProcessVersion".id, "workflowProcessVersion".process_id, "workflowProcessVersion".deployment_id, "workflowProcessVersion".procdef_id, "workflowProcessVersion".proc_key, "workflowProcessVersion".current, "workflowProcessVersion".create_at, "workflowProcessVersion".form_id, "workflowProcessVersion".bpmn_json, "workflowProcessHistories".id, "workflowProcessHistories".procinst_id, "workflowProcessHistories".form_data, "workflowProcessHistories".create_at, "workflowProcessHistories".version_id, "workflowProcessHistories".apply_user
Join Filter: ("workflowProcessVersion".id = "workflowProcessHistories".version_id)
Buffers: shared read=20
-> Seq Scan on public.workflow_process_history "workflowProcessHistories" (cost=0.00..23.94 rows=1 width=397) (actual time=0.253..0.253 rows=0 loops=1)
Output: "workflowProcessHistories".id, "workflowProcessHistories".procinst_id, "workflowProcessHistories".form_data, "workflowProcessHistories".create_at, "workflowProcessHistories".version_id, "workflowProcessHistories".apply_user
Filter: (("workflowProcessHistories".procinst_id)::text = '2b38bb4a-db44-11ec-9537-82994f65ae9b'::text)
Rows Removed by Filter: 285
Buffers: shared read=20
-> Limit (cost=0.00..250.57 rows=10 width=1091) (never executed)
Output: "workflowProcessVersion".id, "workflowProcessVersion".process_id, "workflowProcessVersion".deployment_id, "workflowProcessVersion".procdef_id, "workflowProcessVersion".proc_key, "workflowProcessVersion".current, "workflowProcessVersion".create_at, "workflowProcessVersion".form_id, "workflowProcessVersion".bpmn_json
-> Seq Scan on public.workflow_process_version "workflowProcessVersion" (cost=0.00..18567.58 rows=741 width=1091) (never executed)
Output: "workflowProcessVersion".id, "workflowProcessVersion".process_id, "workflowProcessVersion".deployment_id, "workflowProcessVersion".procdef_id, "workflowProcessVersion".proc_key, "workflowProcessVersion".current, "workflowProcessVersion".create_at, "workflowProcessVersion".form_id, "workflowProcessVersion".bpmn_json
Filter: ((SubPlan 1) IS NOT NULL)
SubPlan 1
-> Limit (cost=0.00..24.73 rows=1 width=4) (never executed)
Output: "workflowProcessHistories_1".version_id
-> Seq Scan on public.workflow_process_history "workflowProcessHistories_1" (cost=0.00..24.73 rows=1 width=4) (never executed)
Output: "workflowProcessHistories_1".version_id
Filter: ((("workflowProcessHistories_1".procinst_id)::text = '2b38bb4a-db44-11ec-9537-82994f65ae9b'::text) AND ("workflowProcessHistories_1".version_id = "workflowProcessVersion".id))
Planning Time: 1.076 ms
Execution Time: 0.333 ms
pg 库构建出一个规划节点的树状结构,来表示不同的操作: 根节点和每个->指向一个操作:
Nested Loop
|___________ Seq Scan
|___________ Limit
|______ Seq Scan
|_____ Limit
|____ Seq Scan
每个分支代表一个子动作,从里到外以确定哪个是“第一个”发生(尽管同一级别的节点顺序可能不同)
在EXPLAIN 命令的输出结果中可能包含多种类型的执行节点,我们可以大体分为几大类:
- 控制节点(Control Node)
- 扫描节点(ScanNode)
- 物化节点(Materialization Node)
- 连接节点(Join Node)
为了更有针对性,本文只介绍扫描节点:
扫描节点,简单来说就是为了扫描表的元组,每次获取一条元组(Bitmap Index Scan除外)作为上层节点的输入。当然严格的说,不光可以扫描表,还可以扫描函数的结果集、链表结构、子查询结果集等。
目前在PostgreSQL 中支持:
Seq Scan: 全表顺序扫描,一般查询没有索引的表需要全表顺序扫描Index Scan: 是索引扫描,主要用来在WHERE 条件中存在索引列时的扫描IndexOnly Scan: 基于索引扫描,并且只返回索引列的值,简称为覆盖索引BitmapIndex Scan: 利用Bitmap 结构扫描BitmapHeap Scan: 把BitmapIndex Scan 返回的Bitmap 结构转换为元组结构Tid Scan: 用于扫描一个元组TID 数组Subquery Scan: 扫描一个子查询Function Scan: 处理含有函数的扫描TableFunc Scan: 处理tablefunc 相关的扫描Values Scan: 用于扫描Values 链表的扫描Cte Scan: 用于扫描WITH 字句的结果集NamedTuplestore Scan: 用于某些命名的结果集的扫描WorkTable Scan: 用于扫描Recursive Union 的中间数据Foreign Scan: 用于外键扫描Custom Scan: 用于用户自定义的扫描
其中,最常用的几个:Seq Scan、Index Scan、IndexOnly Scan、BitmapIndex Scan、BitmapHeap Scan。
结果分析:
Seq Scan on workflow_process_history说明了这个节点的类型和作用对象,即在 'workflow_process_history' 表上进行了全表扫描(cost=0.00..24.73 rows=1 width=4)说明了这个节点的代价估计(actual time=56.036..56.037 rows=0 loops=1)说明了这个节点的真实执行信息,当EXPLAIN 命令中的ANALYZE选项为on时,会输出该项内容Output: ... ...说明 SQL 的输出结果集的各个列,当EXPLAIN 命令中的选项VERBOSE 为on时才会显示Filter: (... ...)说明 Seq Scan 节点之上的Filter 操作,即全表扫描时对每行记录进行过滤操作Rows Removed by Filter: 285表明了过滤操作过滤了多少行记录,属于Seq Scan 节点的VERBOSE 信息,只有EXPLAIN 命令中的VERBOSE 选项为on 时才会显示Buffers: shared read=20说明 从共享缓存中命中了 20 个BLOCK,属于Seq Scan 节点的BUFFERS 信息,只有EXPLAIN 命令中的BUFFERS 选项为on 时才会显示Planning Time: 1.076 ms表示生成查询计划的时间Execution Time: 0.333 ms表示实际的SQL 执行时间,其中不包括查询计划的生成时间rows 代表预估的行数,
width 代表预估的结果宽度,单位为字节
actual time 执行时间,格式为xxx..xxx,在.. 之前的是该节点实际的启动时间,即找到符合该节点条件的第一个结果实际需要的时间,在..之后的是该节点实际的执行时间
rows 指的是该节点实际的返回行数
loops 指的是该节点实际的重启次数。如果一个计划节点在运行过程中,它的相关参数值(如绑定变量)发生了变化,就需要重新运行这个计划节点。
注意事项和限制
您不能EXPLAIN用于所有类型的语句:它仅支持SELECT, INSERT, UPDATE, DELETE, EXECUTE(准备好的语句)CREATE TABLE … AS和DECLARE(游标的)。
请注意,这EXPLAIN ANALYZE会显着增加查询执行时间的开销,因此如果语句花费更长的时间,请不要担心。
查询执行时间总是有一定的变化,因为在第一次执行期间数据可能不在缓存中。这就是为什么重复EXPLAIN ANALYZE几次并查看结果是否改变很有价值的原因。
在EXPLAIN ANALYZE输出中关注什么
- 查找花费大部分执行时间的节点。
- 找到估计行数与实际行数显着不同的最低节点。很多时候,这是性能不佳的原因,其他地方的执行时间长只是基于错误估计的错误计划选择的结果。“显着不同”通常意味着 10 倍左右。
- 使用删除许多行的过滤条件查找长时间运行的顺序扫描。这些都是很好的索引候选对象。
分析工具
depesz 的 EXPLAIN ANALYZE 工具
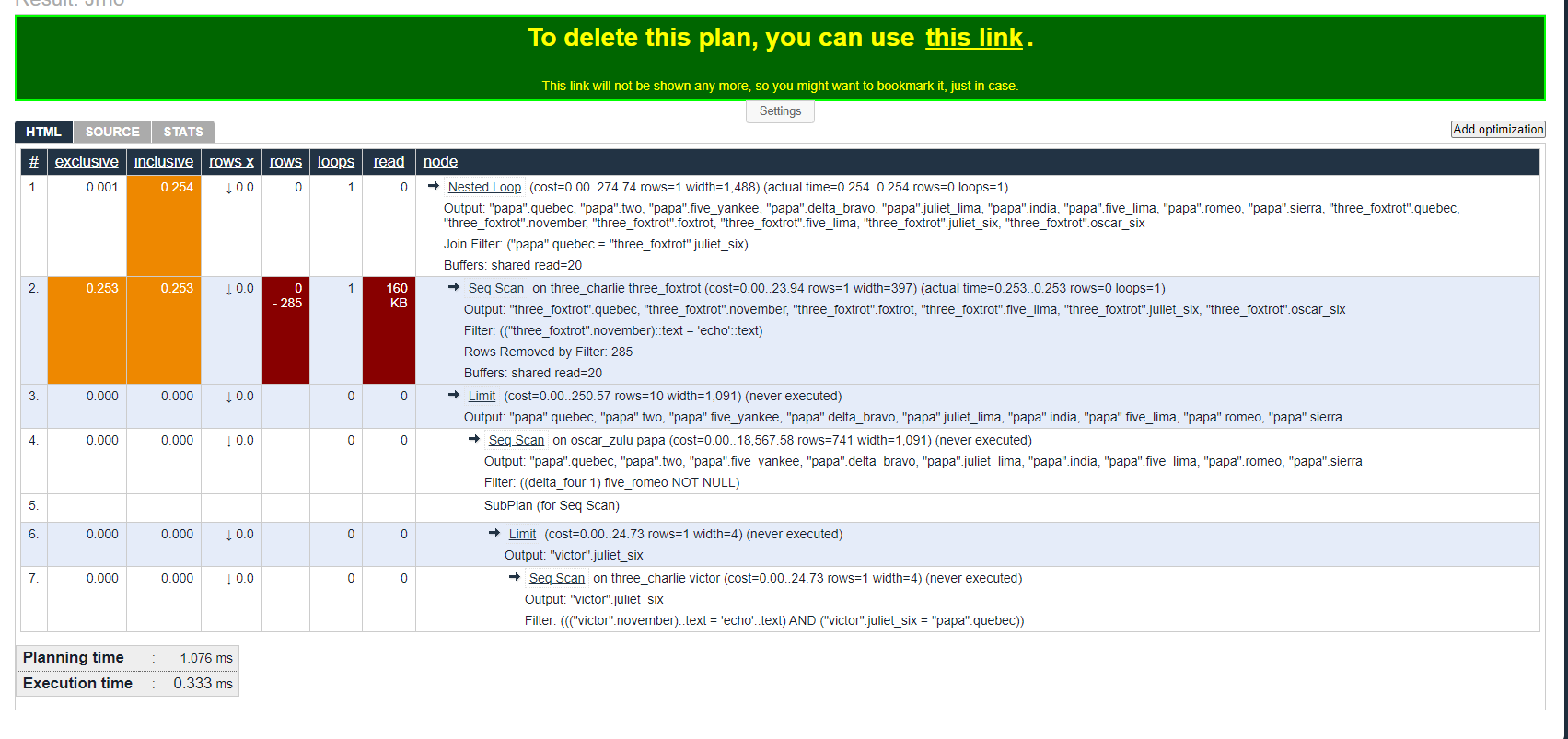
这个执行计划看起来与原始计划有些相似,但看上去好看点。有一些有用的附加功能:
- 计算并显示每个节点的总执行时间和净执行时间。这可以为您节省很多工作!次数最多的节点用红色背景突出显示,很容易被发现。
- 在标题“行 x”下,您可以看到 PostgreSQL 高估或低估了行数的因素。错误的估计以红色背景突出显示。
- 如果您单击一个节点,它下面的所有内容都将隐藏。这使您可以忽略长期执行计划中无趣的部分并专注于重要的部分。
- 如果您将鼠标悬停在一个节点上,它的所有直接子节点都会以星号突出显示。这使得在大型执行计划中找到它们变得容易。
Dalibo 的EXPLAIN ANALYZE 工具
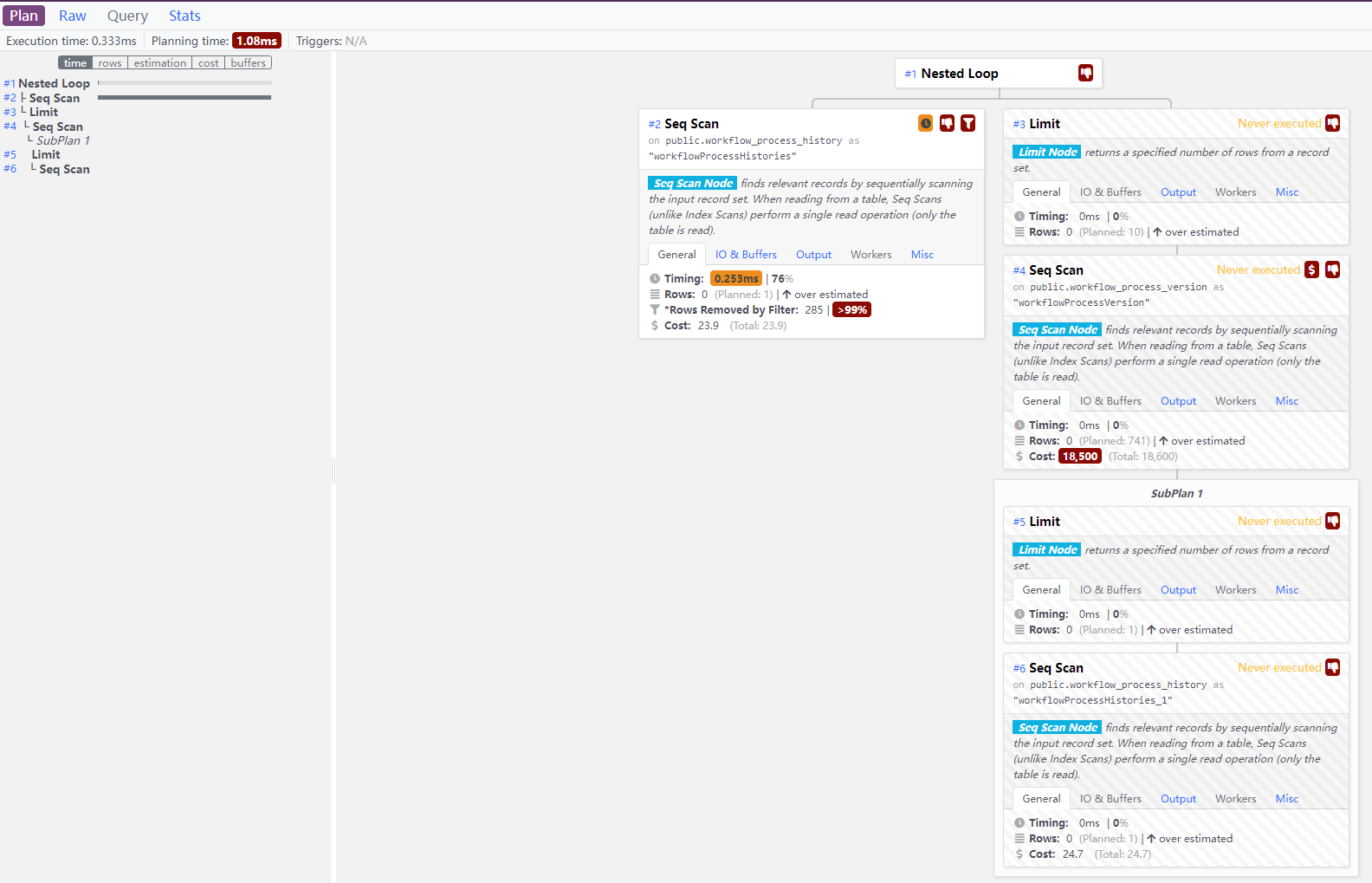
最初,显示会隐藏详细信息,但您可以通过单击一个节点来显示它们,就像我对上图中的第二个节点所做的那样。在左侧,您会看到所有节点的小概览,从那里您可以跳转到右侧以获取详细信息。增加价值的功能是:
- 在左侧,您会看到表示相对净执行时间的条形图,让您可以专注于最昂贵的节点。
- 同样在左侧,您可以选择“估计”以查看 PostgreSQL 高估或低估了每行的行数。
- 最后,您可以单击“缓冲区”以查看哪些节点使用了最多的 8kB 块。这是有用的信息,因为它显示了执行时间取决于数据缓存情况的节点。
- 在右侧,您可以通过单击展开一个节点,并在多个选项卡中获取所有详细信息, 您可以通过单击隐藏在节点右下角的“十字准线”图标来折叠树中节点下的所有内容。
一些结论
- 大多数情况下,Index Scan 要比 Seq Scan 快。但是如果获取的结果集占所有数据的比重很大时,这时Index Scan 因为要先扫描索引再读表数据反而不如直接全表扫描来的快。
- 如果获取的结果集的占比比较小,但是元组数很多时,可能Bitmap Index Scan 的性能要比Index Scan 好。
- 如果获取的结果集能够被索引覆盖,则Index Only Scan 因为不用去读数据,只扫描索引,性能一般最好。但是如果VM 文件未生成,可能性能就会比Index Scan 要差。
上面的结论都是基于理论分析得到的结果,但是其实PostgreSQL 的EXPLAIN 命令中输出的cost,rows,width 等代价估计信息中已经展示了这些扫描节点或者其他节点的预估代价,通过对预估代价的比较,可以选择出最小代价的查询计划树。