k8s 集群部分常见问题及处理
问题处理过程中常用的命令
# 查看节点
> kubectl get node [-o wide]
# 查看节点事件
> kubectl describe node ${k8s-node} --show-events
# 查看k8s pod
> kubectl get pod -n kube-system -o wide
# 查看 k8s pod
> kubectl describe pod ${pod_name} -n kube-system
# 查看 pod 日志
> kubectl logs ${pod_name} -n kube-system
# 查看日志
> journalctl -u kubelet -f
# 查看配置
> kubectl get pod ${pod_name} [-n ${namespace}] -o yaml
> kubectl get svc ${svc_name} [-n ${namespace}] -o yaml
> kubectl get deployments ${deployment} -o yaml
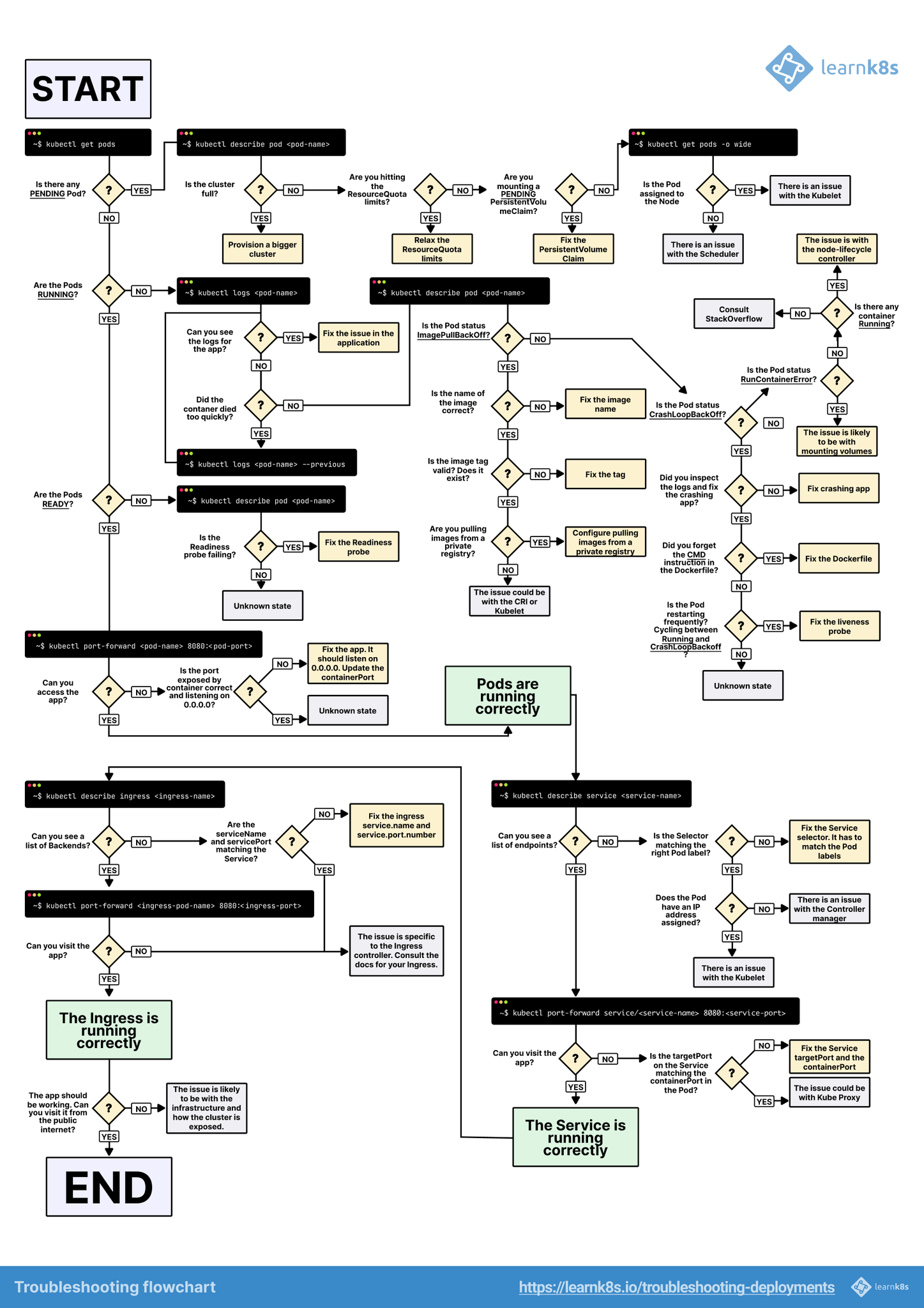
常见问题及处理
Node NotReady
缺少配置文件
如果是新加入的节点,查看下 flannel 网络是否可以初始化,如果不能,可能就是缺少配置文件
# 查看 节点 `/etc/cni/net.d `
> ls /etc/cni/net.d
# 如果没有该路径,手动创建目录
> mkdir -p /etc/cni/net.d
# 拷贝配置文件到节点主机
> scp test-master:/etc/cni/net.d/* /etc/cni/net.d/
查看日志
> journalctl -u kubelet -f
server.go:266] failed to run Kubelet: Running with swap on is not supported, please disable swap! or set --fail-swap-on flag to false. /proc/swaps contained: [Filename
swap没有关掉ps: ubuntu16 无法永久关闭
swap,经常开机后swap还是有可能自动挂载
> swapoff -a
> journalctl -u kubelet -f
Error: "MountVolume.SetUp failed for volume \"flannel-token-4g7bs\" (UniqueName: \"kubernetes.io/secret/96cbc74a-58d5-4d10-b7df-52732ba63938-flannel-token-4g7bs\") pod \"kube-flannel-ds-amd64-j7bl2\" (UID: \"96cbc74a-58d5-4d10-b7df-52732ba63938\") : failed to sync secret cache: timed out waiting for the condition"
解决:
# 编辑 `/var/lib/kubelet/config.yaml`,追加:
featureGates:
CSIMigration: false
# 然后重启 `kubelet`
> service kubelet restart
pod 被调度到节点后无法启动,或无法正常通信
flannel网络有问题
查看日志或pod详情
1.
NetworkPlugin cni failed to set up pod "demo-deployment-675b5f9477-hdcwg_default" network: failed to set bridge addr: "cni0" already has an IP address different from 10.0.2.1/24
重置节点
> kubeadm reset #重置节点
> systemctl stop kubelet && rm -rf /var/lib/cni/ && rm -rf /var/lib/kubelet/* && rm -rf /var/lib/etcd && rm -rf /etc/cni/
> ifconfig cni0 down && ifconfig flannel.1 down && ifconfig docker0 down
> ip link delete cni0 && ip link delete flannel.1
> systemctl restart docker
> systemctl start kubelet
重新生成token并注册节点即可
# 重新获取 kubeadm join 命令
> kubeadm token create --print-join-command [--ttl=0]
2.
"open /run/flannel/subnet.env: no such file or directory"
解决方案:
查看从其他节点的文件创建一个:
FLANNEL_NETWORK=10.244.0.0/16
FLANNEL_SUBNET=10.244.0.1/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true
pod 内无法访问外网
检查CoreDNS组件的配置
coredns的ConfigMap
注意:
coredns镜像各版本的差异配置
# image: coredns/coredns:1.7.0
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
data:
Corefile: |
.:53 {
errors
health {
lameduck 5s
}
hosts {
10.8.30.157 test-master
10.8.30.152 test-n1
10.8.30.156 test-n2
10.8.30.155 test-n3
10.8.30.161 test-n4
10.8.30.158 test-n5
10.8.30.35 node35
10.8.30.36 node36
10.8.30.37 node37
10.8.30.38 node38
10.8.30.39 node39
fallthrough
}
ready
kubernetes CLUSTER_DOMAIN REVERSE_CIDRS {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153
forward . /etc/resolv.conf
cache 30
loop
reload
loadbalance
}
pod 其他常见问题
pod一直处于pending状态表示该pod没有被调度到这个节点上,通常是由于资源不足造成的
解决方案,就是增加资源:
- 增加工作节点
- 移除部分pod来释放资源
- 调低当前pod的资源限制
pod一直处于waiting状态pod 卡在
waiting,说明 这个pod 已经调度到这个节点,但是没有运行起来可能是由于镜像拉取失败造成的
解决方案:
- 检查网络,
- 考虑镜像加速
- 使用
docker pull <image>来验证镜像是否正常拉取
pod一直处于CrashLoopBackOff状态这个说明容器曾经启动过,它的重启次数是大于0的,无法通过健康检查
- 一个是镜像制作的问题,镜像内app无法正常运行,检查app和镜像制作过程 2. 重新设置合适的健康检查阈值
- 优化容器的性能,提高启动速度
- 关闭健康检查
delete namespace satus 一直处于 Terminating
namespace一直处于Terminating状态,无法删除
➜ ~ kubectl get ns
NAME STATUS AGE
k8tz Active 27d
kruise-system Active 29d
kube-public Active 261d
kube-system Active 261d
kubernetes-dashboard Active 159d
kubesphere-logging-system Terminating 18h
kubesphere-monitoring-federated Active 18h
kubesphere-monitoring-system Active 18h
kubesphere-system Active 16h
openelb-system Active 18d
1. 正常删除
➜ ~ kubectl delete ns kubesphere-logging-system
# 无响应
2. 强制删除
➜ ~ kubectl delete ns kubesphere-logging-system --force --grace-period=0
warning: Immediate deletion does not wait for confirmation that the running resource has been terminated. The resource may continue to run on the cluster indefinitely.
namespace "kubesphere-logging-system" force deleted
# 无响应
3. 编辑删除
将
finalizers内容删掉
➜ ~ kubectl edit ns kubesphere-logging-system
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: v1
kind: Namespace
metadata:
creationTimestamp: "2022-08-23T06:57:25Z"
deletionTimestamp: "2022-08-24T01:29:23Z"
labels:
kubernetes.io/metadata.name: kubesphere-logging-system
name: kubesphere-logging-system
resourceVersion: "69843859"
uid: 1755de4b-3f4d-4dd8-9d0f-cb21a0d1616b
spec:
finalizers:
- kubernetes # 删除 , 改成 []
status:
conditions:
- lastTransitionTime: "2022-08-24T01:29:29Z"
message: All resources successfully discovered
reason: ResourcesDiscovered
status: "False"
type: NamespaceDeletionDiscoveryFailure
- lastTransitionTime: "2022-08-24T01:29:29Z"
message: All legacy kube types successfully parsed
reason: ParsedGroupVersions
status: "False"
type: NamespaceDeletionGroupVersionParsingFailure
- lastTransitionTime: "2022-08-24T01:29:29Z"
message: All content successfully deleted, may be waiting on finalization
reason: ContentDeleted
status: "False"
type: NamespaceDeletionContentFailure
- lastTransitionTime: "2022-08-24T01:29:29Z"
message: 'Some resources are remaining: exporters.events.kubesphere.io has 1 resource
instances, rulers.events.kubesphere.io has 1 resource instances'
reason: SomeResourcesRemain
status: "True"
type: NamespaceContentRemaining
- lastTransitionTime: "2022-08-24T01:29:29Z"
message: 'Some content in the namespace has finalizers remaining: exporters.finalizer.events.kubesphere.io
in 1 resource instances, rulers.finalizer.events.kubesphere.io in 1 resource
instances'
reason: SomeFinalizersRemain
status: "True"
type: NamespaceFinalizersRemaining
phase: Terminating
4. 调接口删除
➜ ~ kubectl get ns kubesphere-logging-system -o json > logging-system.json
➜ ~ vi logging-system.json
# 删除 spec 及 status 部分,剩下内容如下:
{
"apiVersion": "v1",
"kind": "Namespace",
"metadata": {
"creationTimestamp": "2022-08-23T06:57:25Z",
"deletionTimestamp": "2022-08-24T01:29:23Z",
"labels": {
"kubernetes.io/metadata.name": "kubesphere-logging-system"
},
"name": "kubesphere-logging-system",
"resourceVersion": "69843859",
"uid": "1755de4b-3f4d-4dd8-9d0f-cb21a0d1616b"
}
}
# 启动代理
➜ ~ kubectl proxy
# 调接口删除
➜ ~ curl -k -H "Content-Type: application/json" -X PUT --data-binary @logging-system.json http://127.0.0.1:8001/api/v1/namespaces/kubesphere-logging-system/finalize
NAMESPACE=<your-namespace>
kubectl get namespace $NAMESPACE -o json > $NAMESPACE.json
sed -i -e 's/"kubernetes"//' $NAMESPACE.json
kubectl replace --raw "/api/v1/namespaces/$NAMESPACE/finalize" -f ./$NAMESPACE.json
其他问题
# 查看日志得到:
github.com/coredns/coredns/plugin/kubernetes/controller.go:322: Failed to list *v1.Namespace: Get https://10.96.0.1:443/api/v1/namespaces?limit=500&resourceVersion=0: dial tcp 10.96.0.1:443: connect: no route to host
# 这问题很有可能是防火墙(iptables)规则错乱或者缓存导致的,可以依次执行以下命令进行解决:
> systemctl stop kubelet
> systemctl stop docker
> iptables --flush
> iptables -tnat --flush
> systemctl start kubelet
> systemctl start docker
Initial timeout of 40s passed. [kubelet-check] It seems like the kubelet isn't running or healthy. [kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp 127.0.0.1:10248: connect: connection refused. [kubelet-check] It seems like the kubelet isn't running or healthy.
Unfortunately, an error has occurred: timed out waiting for the condition
This error is likely caused by:
- The kubelet is not running
- The kubelet is unhealthy due to a misconfiguration of the node in some way (required cgroups disabled)
最后发现节点上缺少 /etc/systemd/system/kubelet.service.d/10-kubeadm.conf 这个文件,补上就好了
$ vi /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
# Note: This dropin only works with kubeadm and kubelet v1.11+
[Service]
Environment="KUBELET_KUBECONFIG_ARGS=--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf"
Environment="KUBELET_CONFIG_ARGS=--config=/var/lib/kubelet/config.yaml"
# This is a file that "kubeadm init" and "kubeadm join" generates at runtime, populating the KUBELET_KUBEADM_ARGS variable dynamically
EnvironmentFile=-/var/lib/kubelet/kubeadm-flags.env
# This is a file that the user can use for overrides of the kubelet args as a last resort. Preferably, the user should use
# the .NodeRegistration.KubeletExtraArgs object in the configuration files instead. KUBELET_EXTRA_ARGS should be sourced from this file.
EnvironmentFile=-/etc/default/kubelet
ExecStart=
ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS
deployment.yaml丢失怎么删除pod
# 查看 pods 列表
kubectl get deployment -n XXX
# 根据pod名称删除
kubectl delete deployment xxx(NAME) -n XXX
Orphaned pod found - but volume paths are still present on disk
Jul 27 15:04:24 jump-01 kubelet[1162]: E0727 15:04:24.635473 1162 kubelet_volumes.go:154] orphaned pod "a7b6a421-5b66-4c5a-bb62-b2917ecebe01" found, but volume paths are still present on disk : There were a total of 3 errors similar to this. Turn up verbosity to see them.
直在刷报错,从错误信息可以推测到,这台计算节点存在一个孤儿Pod,并且该Pod挂载了数据卷(volume),阻碍了Kubelet对孤儿Pod正常的回收清理
通过id号,进入kubelet的目录,可以发现里面装的是容器的数据,etc-hosts文件中还保留着podname
# cd /var/lib/kubelet/pods/a7b6a421-5b66-4c5a-bb62-b2917ecebe01
/var/lib/kubelet/pods/a7b6a421-5b66-4c5a-bb62-b2917ecebe01# ls
containers etc-hosts plugins volumes
/var/lib/kubelet/pods/a7b6a421-5b66-4c5a-bb62-b2917ecebe01# cat etc-hosts
# Kubernetes-managed hosts file.
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
fe00::0 ip6-mcastprefix
fe00::1 ip6-allnodes
fe00::2 ip6-allrouters
172.16.1.180 termail-2509590746-mw56s
解决
首先通过etc-hosts文件的pod name 发现已经没有相关的实例在运行了,然后按照issue中的提示,删除pod
rm -rf a7b6a421-5b66-4c5a-bb62-b2917ecebe01
但是这个方法有一定的
危险性,还不确认是否有数据丢失的风险,如果可以确认,再执行。或在issue中寻找更好的解决方法
补充
kubectl-debug
kubectl-debug 是一个简单的开源的kubectl 插件, 可以帮助我们便捷地进行 Kubernetes 上的 Pod 排障诊断,背后做的事情很简单:
在运行中的 Pod 上额外起一个新容器, 并将新容器加入到目标容器的 pid, network, user以及 ipc namespace中,
这时我们就可以在新容器中直接用 netstat, tcpdump 这些熟悉的工具来诊断和解决问题了, 而旧容器可以保持最小化,
不需要预装任何额外的排障工具
安装
> export PLUGIN_VERSION=0.1.1
# linux x86_64,下载文件
> curl -Lo kubectl-debug.tar.gz https://github.com/aylei/kubectl-debug/releases/download/v${PLUGIN_VERSION}/kubectl-debug_${PLUGIN_VERSION}_linux_amd64.tar.gz
#解压
> tar -zxvf kubectl-debug.tar.gz kubectl-debug
#移动到用户的可执行文件目录
> sudo mv kubectl-debug /usr/local/bin/
# 部署 debug-agent daemonset
kubectl apply -f https://raw.githubusercontent.com/aylei/kubectl-debug/master/scripts/agent_daemonset.yml
或者使用 helm 安装
helm install -n=debug-agent ./contrib/helm/kubectl-debug
常用命令
# 输出帮助命令
> kubectl debug -h
# 启动Debug
> kubectl debug (POD | NAME)
# 假如 Pod 处于 CrashLookBackoff 状态无法连接, 可以复制一个完全相同的 Pod 来进行诊断
> kubectl debug (POD | NAME) --fork
# 假如 Node 没有公网 IP 或无法直接访问(防火墙等原因), 请使用 port-forward 模式
> kubectl debug (POD | NAME) --port-forward --daemonset-ns=kube-system --daemonset-name=debug-agent
k8s 健康检查
> kubectl get componentstatus
# 或
> kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true"}
# 检查 kubelet、docker等服务是否在运行 (active)
> systemctl status kubelet docker
# k8s 组件
> kubectl get pods -o wide -n kube-system
k8s组件主要分为Master组件和节点组件,
Master组件对集群做出全局性决策(比如调度), 以及检测和响应集群事件。
如果Master组件出现问题,可能会导致集群不可访问,Kubernetes API 访问出错,各种控制器无法工作等等。
而节点组件在每个节点上运行,维护运行的Pod并提供 Kubernetes运行时环境。
如果节点组件出现问题,可能会导致该节点异常并且该节点Pod无法正常运行和结束
kube-apiserver
对外暴露了Kubernetes API,如果kube-apiserver出现异常可能会导致:
- 集群无法访问,无法注册新的节点
- 资源(Deployment、Service等)无法创建、更新和删除
- 现有的不依赖Kubernetes API的pods和services可以继续正常工作
etcd
etcd用于Kubernetes的后端存储,所有的集群数据都存在这里。保持稳定的etcd集群对于Kubernetes集群的稳定性至关重要。
因此,我们需要在专用计算机或隔离环境上运行etcd集群以确保资源需求。当etcd出现异常时可能会导致:
- kube-apiserver无法读写集群状态,apiserver无法启动
- Kubernetes API访问出错
- kubectl操作异常
- kubelet无法访问apiserver,仅能继续运行已有的Pod
kube-controller-manager和kube-scheduler
kube-controller-manager和kube-scheduler分别用于控制器管理和Pod 的调度,如果他们出现问题,则可能导致:
- 相关控制器无法工作
- 资源(Deployment、Service等)无法正常工作
- 无法注册新的节点
- Pod无法调度,一直处于Pending状态
kubelet
kubelet是主要的节点代理,如果节点宕机(VM关机)或者kubelet出现异常(比如无法启动),那么可能会导致:
- 该节点上的Pod无法正常运行,如果节点关机,则当前节点上所有Pod都将停止运行
- 已运行的Pod无法伸缩,也无法正常终止
- 无法启动新的Pod
- 节点会标识为不健康状态
- 副本控制器会在其它的节点上启动新的Pod
- Kubelet有可能会删掉当前运行的Pod
CoreDNS
CoreDNS(在1.11以及以上版本的Kubernetes中,CoreDNS是默认的DNS服务器)是k8s集群默认的DNS服务器,如果其出现问题则可能导致:
- 无法注册新的节点
- 集群网络出现问题
- Pod无法解析域名
kube-proxy
kube-proxy是Kubernetes在每个节点上运行网络代理。如果它出现了异常,则可能导致:
- 该节点Pod通信异常